
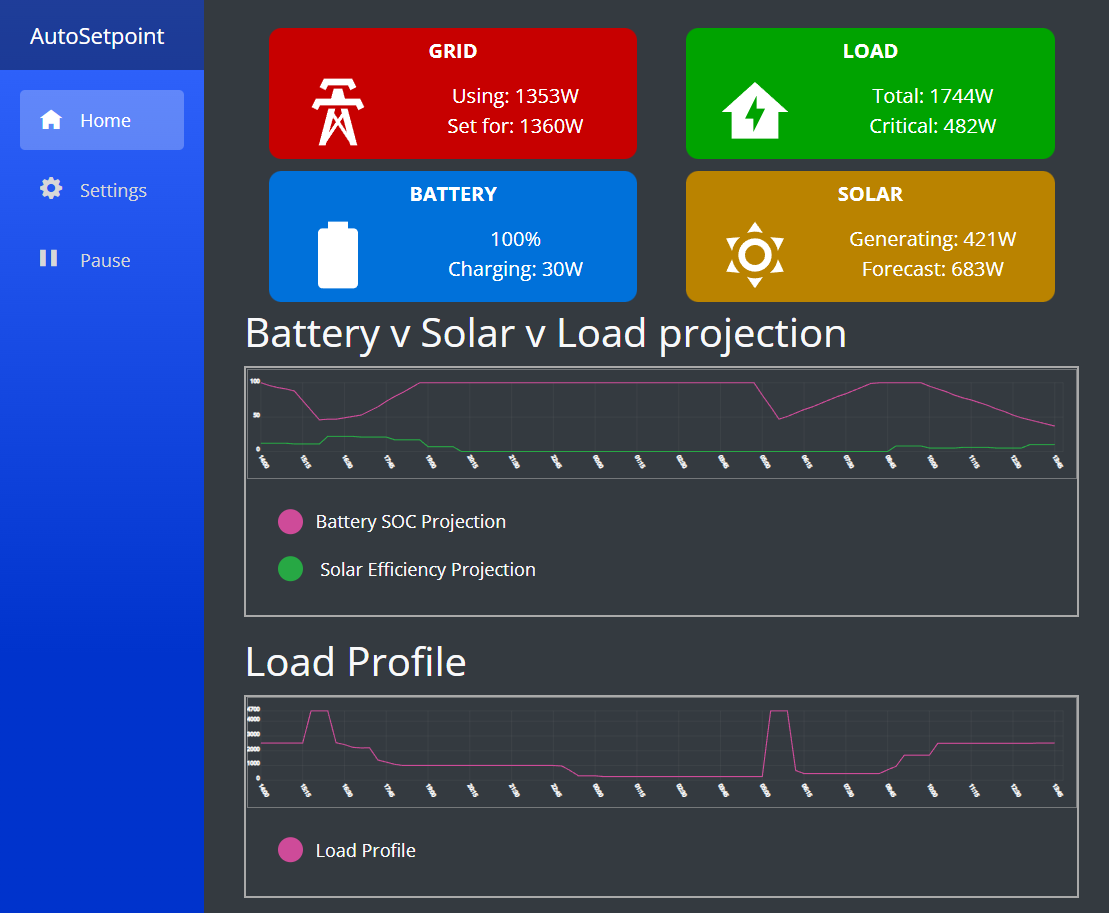
Setting up a simulation for hanging cables in Blender has a few steps, including the scale, goals and potentially hooks. Let's dive in.

- This blog post was made using Blender 2.83.3 and Unreal Engine 4.26.2
If you haven’t read it, check out part 1 for what we’re importing today.
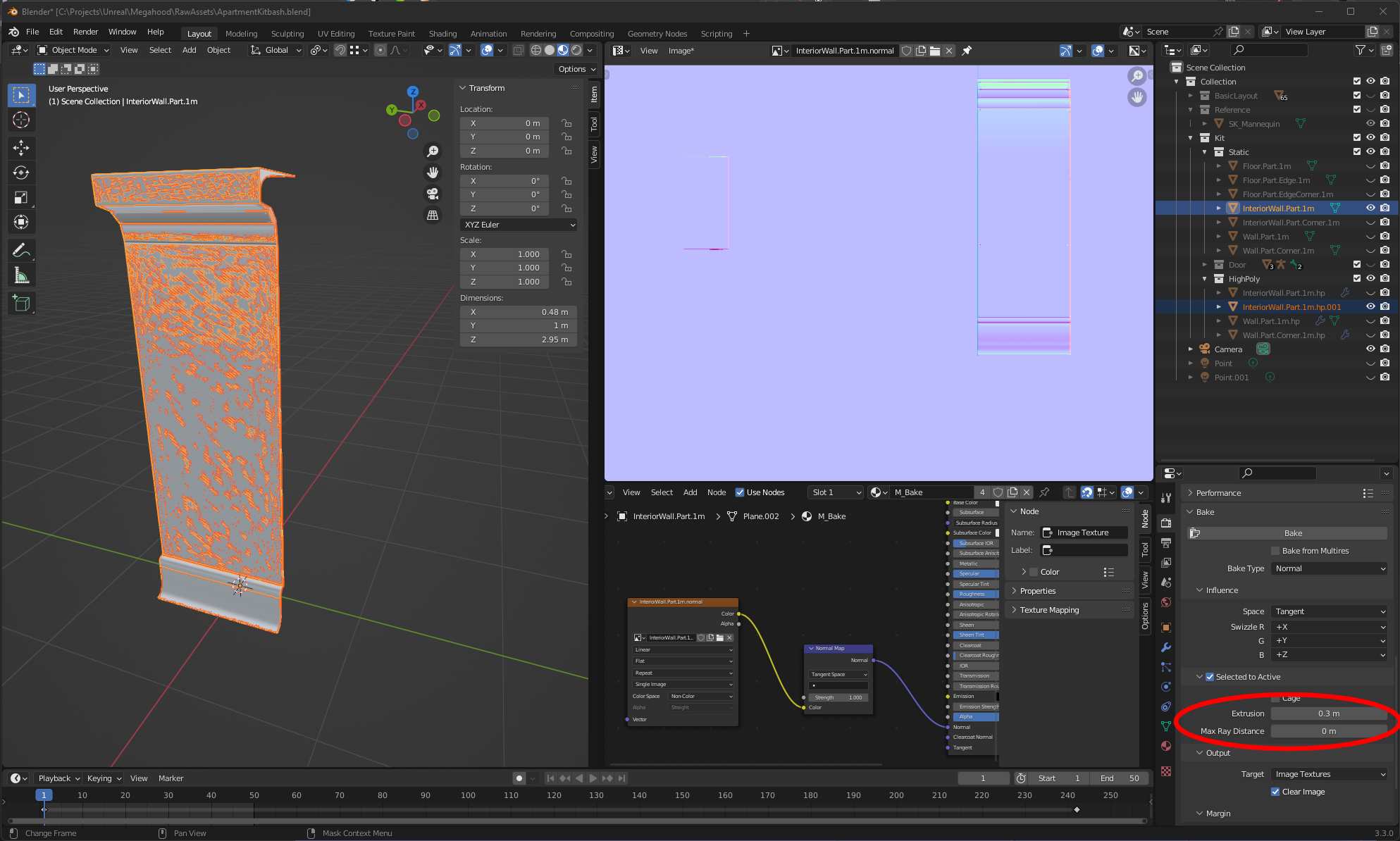
Now that we have our sliding door animation sorted, we need to bring it into the game engine to make use of it. In Blender, the hierarchy currently shows the armature as the main node of this mechanism, and the two door geom...