Published on 5/14/2019
In this part we're still designing, but moving one down from the high level overview in part 1.
The Solution Architecture - Blog
The next logical level down from the domain level is the Solution Architecture level. This is the first "technical" level. We’ll focus on the blog “continent” of the domain. We already have two concepts here, the Blog entity and the IBlogOwner interface. As explained in part 1, it makes sense that the main entity will have a property that points to its owner, some instance of IBlogOwner. Now let’s look at the type of interactions the blog post has:
- Read
- Create
- Publish
We’re creating blog posts, obviously. And we want to read the blog post back to the user. Obviously the blog post has to be persisted somewhere, like a database. I don’t care for now what database though. Secondly, we need to publish. What does that mean? Pretend we delve into the detail requirements document and we come up with the following text:
A blog post will remain invisible to the public until published. When a blog post is published it should post to selected social media outlets, including the RSS feed.
Actors
This alludes to quite a few actors that we need to keep in mind. "Actors" is a collective term for all the things that you will have to integrate with, whether it is humans, 3rd-party APIs, databases or something on the other side of an abstraction. We already abstracted one actor away - the blog owner. We can probably do the same for all the others. Let’s list all of them, and then see where we are:
- User Interface - the user can read it
- Database - we have to persist
- Owner - the instance of
IBlogOwner - A social media outlet
- Another social media outlet
- Another social media outlet
- … you get the idea
So which are the low-hanging fruit here? Some of these look suspiciously the same, and we can probably lob them all under one abstraction and forget about them for now. Let’s call that one IBlogSyndication. What do we know about the user interface? Is it web? Is it an app?
User Interface
To be honest I don’t want to think about the type of UI until the end. There is some new tech (Blazor) that is still maturing that I want to consider first. So we want an abstraction here. But there doesn’t have to be an abstraction on the blog domain for it, meaning it doesn’t have to point to something. The UI calls "down" the stack and we just need to deliver the blog data (the content) to it. In that regard there is no dependency to define or invert. We can easily build and test our domain without knowing about the UI. But we have to define a service to build. The UI has to call something, and that something we refer to as a service since (for now) it serves the needs of the UI. Let’s name it BlogService. So this will have some API that the UI can call, and it will return the blog content, probably the Blog model itself. And something that can be called and returns something is also a method or a property. And these belong to classes (at least in C#). So here we have a special type of entity. It’s called a concrete class. It provides an implementation of the business rules and serves the data. In contrast, the Blog model is a model class (it can also be a struct) - it is a simple representation of a blog post and it’s associated data, typically referred to as a POCO.
Database and the Repository Pattern
The next item on the list is the database - we have to persist. Now, there is some best-practice process here that we first have to discuss. A lot of Microsoft articles talk about the repository pattern. There is some underlying culture that says "repository" is a synonym for database code - that it is a special pattern for that specific use-case related to persistence. And while 90% of your work will be to persist in a database that you control, it might not always be the case. As such, I don’t regard it as special.
Break the mould
Any place that you talk to to send data is persisting data. It doesn’t matter if it ends up in your database, or via the Facebook API in their database. The point is that it is persisted. You will never see the database on Facebook’s side, but it is still persisted. This is why I prefer to refer to the Adaptor pattern. It’s simply a catch-all term for a specific kind of implementation that assists in abstracting away the details of a specific method of persistence. It is the general form of a repository pattern.
So back to the Database
But don’t confuse this with an ORM. An (O)bject-(R)elational (M)apping library (like Entity Framework) does not serve the same purpose or role as an adaptor service. Specifically, the database tables don’t necessarily map directly to your domain’s model entities. For example, I can guarantee you that the Facebook API POST models looks nothing like our Blog model will. So the adaptor that we need to provide is responsible for mapping to and from our domain model entities to the data models of whatever underlying technology is persisted to. We can refer to this adaptor as the IBlogDatabaseAdaptor, but we’re not going to provide an implementation for it yet.
SOLID: S for Single Responsibility
But what will use this adaptor? The Blog model entity itself, or the BlogService concrete? Consider the following: The UI needs to show some content. That content is represented by the Blog model, so it has to be given an instance of Blog that contains (or represents) that content. Where will it go to get this instance? Perhaps we can add methods onto this Blog model itself? That would violate the first SOLID principle: stick to one purpose. If we bastardize the Blog model like this it becomes cluttered and shares immutable properties that defines a state with stateless method calls. For example, you’ll likely have a Title property (the title of the blog) and also something like GetByTitle(string title) method. You’ll be fielding all sorts of questions from those who make use of your domain library, like "Does GetByTitle return this instance or a different instance?" and "What happens if the title parameter doesn’t match the Title property of this instance?" It becomes clear we should separate that out, and that having the UI rather use BlogService is a better proposition. Now we can contain the orchestration of blog entries in the service and keep it separate from the blogs themselves. But the service isn’t concerned by how to look in the database at all, only with what in the database should be looked at (e.g. it orchestrates to the correct function call). It can refer to the adaptor abstraction which knows how to look into the database and how to convert that from database models (tables) to domain models (POCOs). So with the information that we have now, let’s make BlogService depend on IBlogDatabaseAdaptor. We’ve just deferred another decision!
Justification for Abstractions
You might be thinking "we’re creating more abstractions than we have entities in the domain". And that would be exactly what we need to do in order to isolate ourselves from dependencies and implementation details. But why the isolation?
- Design in isolated chunks: We’ve already seen how the abstractions has limited our scope and enabled us to break our design sessions into different pieces. This even allows different teams to focus on each of the different pieces (sounds like micro services?).
- Strongly-typed interactions: By using language features to define the abstractions (typically an interface or abstract class), we define the methods and actions of interactions between different entities in the strongest possible terms - an unambiguous source code file that you can compile your code against (this mostly only applies to typed languages).
- Keep your domain fit for purpose: When you start dealing with interactions between your domain and other things (database, 3rd party API etc), you invariably come across mismatches between the models in your domain and theirs. It could be something simple like
NamebecomesTitle, or something more complicated like an API Token that you have to carry along for authentication and sometimes renew when it expires. Using abstractions keeps your domain clean, and it’s the job of the implementations of those abstractions at the edges to deal with those mismatches. You can also view it as applying Single Responsibility on a domain level - that is to say your domain should only be concerned with representing your domain and should not include bits and pieces from someone else’s domain. - Test Driven Development: This is a method of working that requires you to first know how to test a feature before you even build the feature. After all, how are you going to prove that your code is working? Abstractions is the only way to achieve unit testing in isolation. Can you always rely on that Facebook API to be available when you want to test? Or perhaps you need to test for a very specific bug under very specific circumstances. What would be required to be setup and configured before you can perform your test? When you have your dependencies as abstractions, you can easily provide mocks for all of them. This means that you can construct a very specific narrative in order to test that one really tough bug. It also means that you can test posting a blog without requiring a valid Facebook account and API key to post against, even when you manually test your code. We’ll cover this in more detail in future posts (part 7 and 8).
Diagram
Let's put up the solution architecture diagram with what we've covered so far:
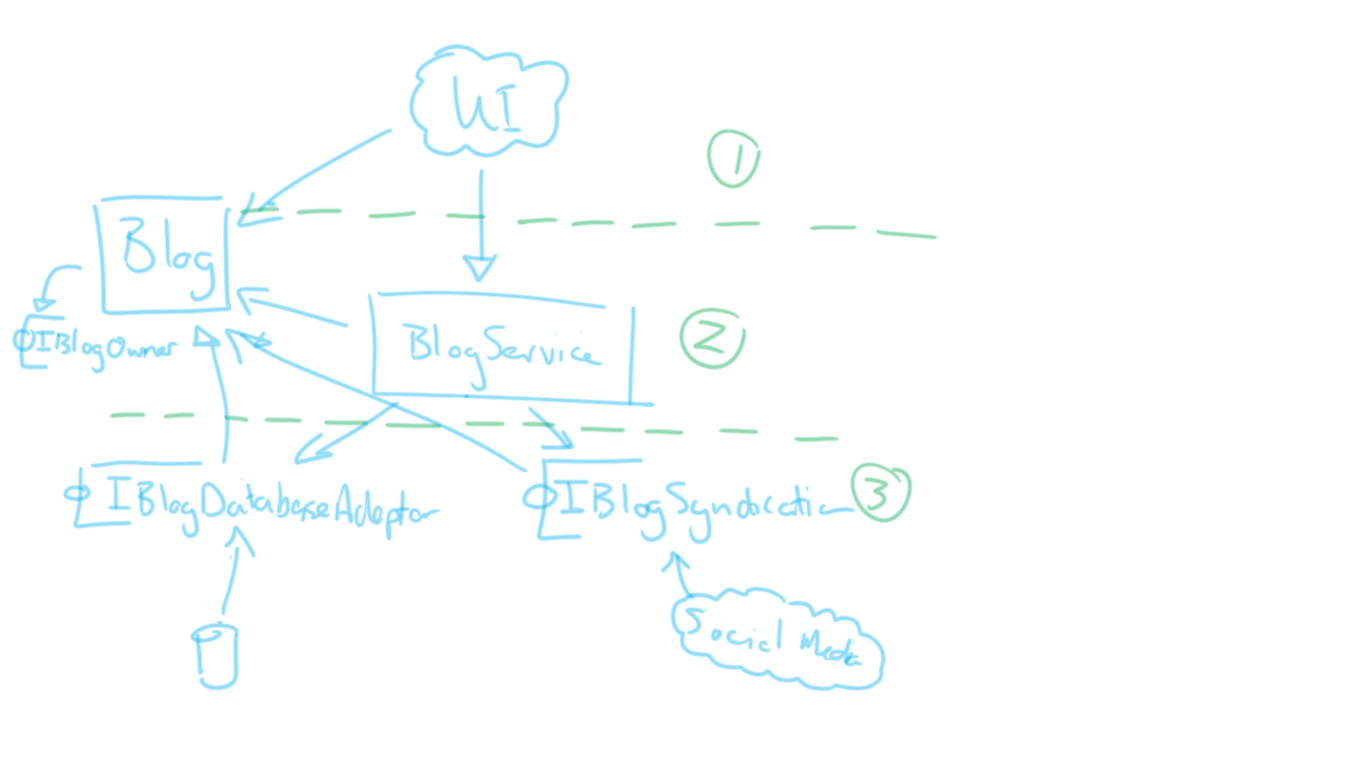
Cross-cutting concerns
In the diagram above there are a lot of dependency arrows. The most referenced item is the Blog model. But there are other items that have more than one arrow pointing to them also. Those are the two adaptor interfaces. Both BlogService and any implementations of those adaptors depend on them. And they in turn depend on Blog itself. Here is where we start to see some common dependencies, and we can try to extract these into its own "group". Often you’ll see a namespace in a project like helloserve.CrossCutting or helloserve.Domain.Common or helloserve.Domain.Shared. Microsoft has opted to establish a standard within the .NET code bases now using the actual term: Abstractions. Clearly this "group" that we are talking about here is just a collection of abstractions and the commonly used types (e.g. models) that they rely on. So, we’ll refer to this group by its eventual namespace helloserve.Domain.Abstractions. Let's redraw:
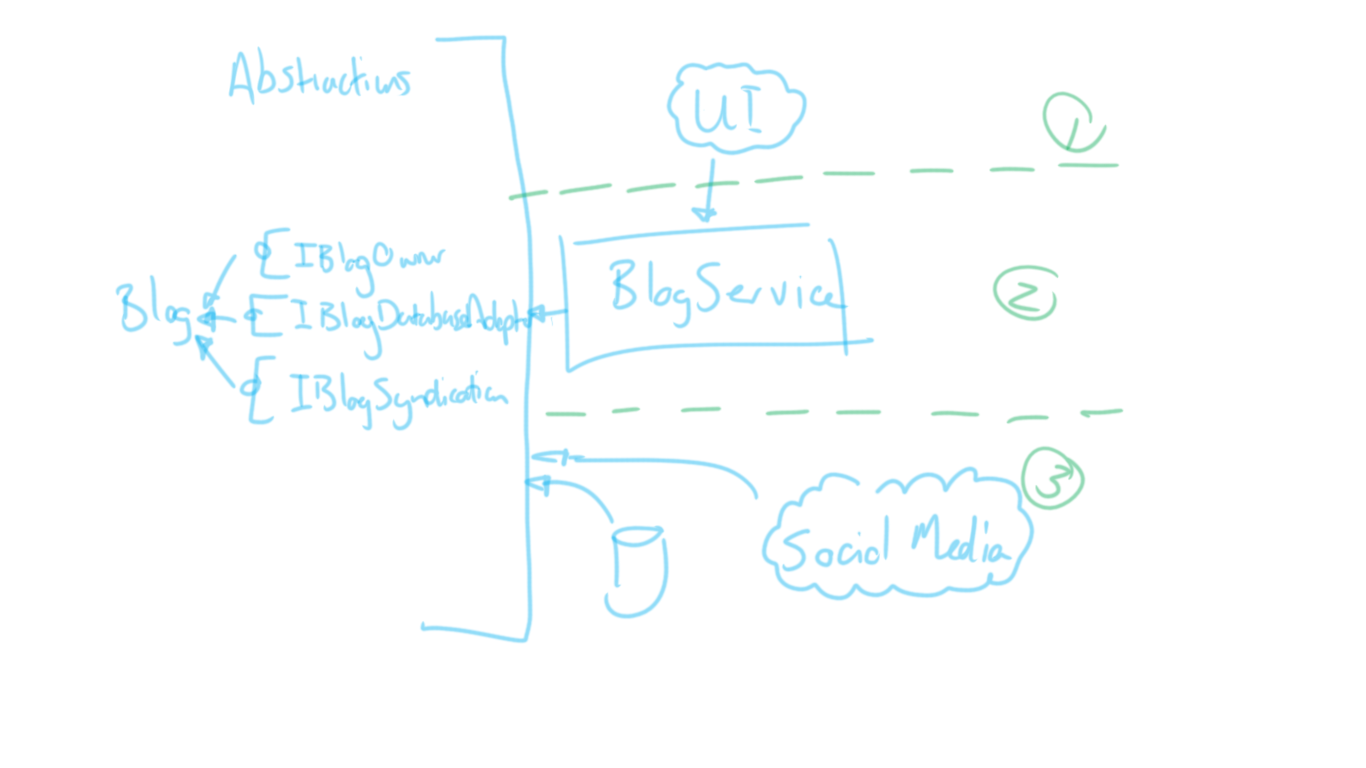
A lot of the arrows are omitted now, and points to the collective abstractions block instead. This is because, in a more involved design, having arrows all over the place gets really messy (it's easier to include it in a nice structured drawing using Visio or Draw.io). That is why the names of these items are so important. It’s clear that the universal glyph for a database should be associated with the IBlogDatabaseAdaptor abstraction because of our wonderfully descriptive name, for instance.
But there is another way to visualize this, and that’s through the onion layer diagram:
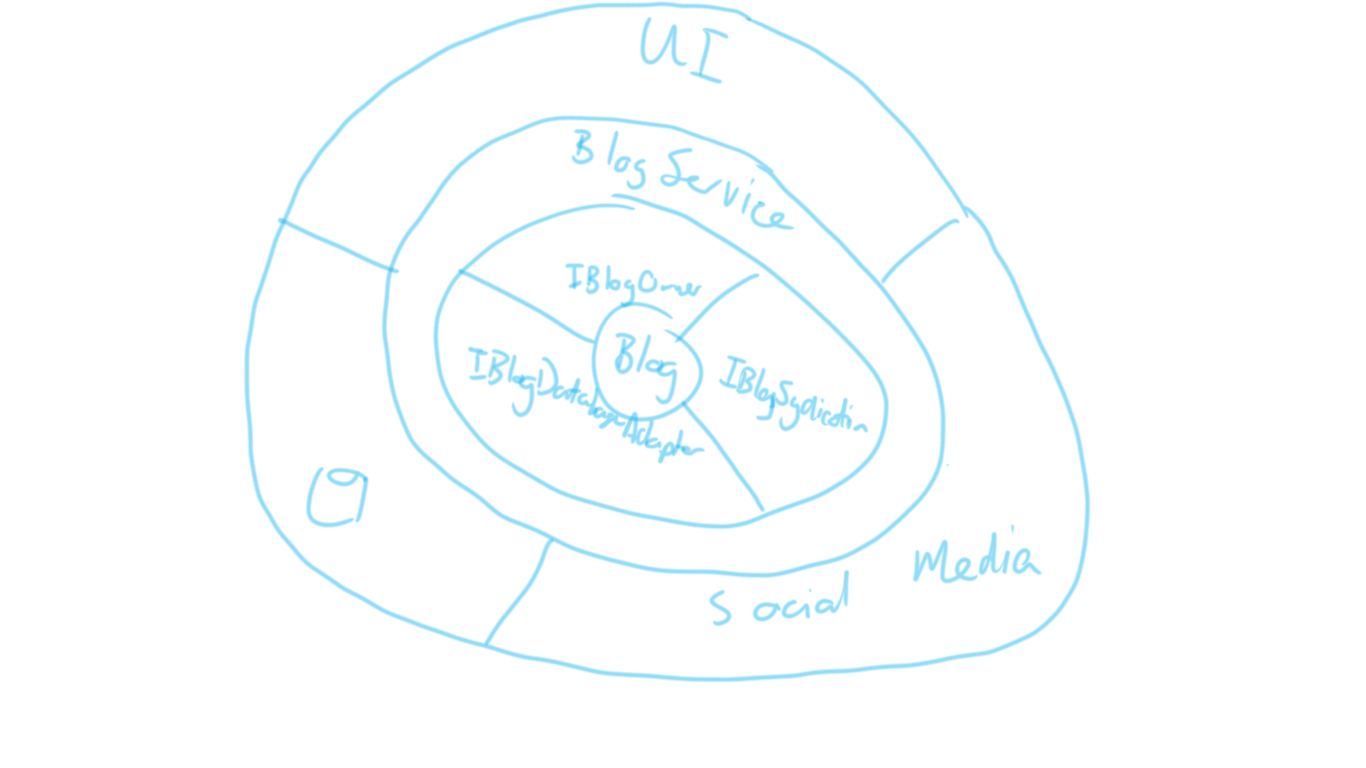
Here the dependencies are easily visualized, with the most dependent in the middle. However, there is still some indirect association (database and its adaptor for example), plus this diagram doesn’t illustrate the different tiers so clearly.
Concept: Common 3-tier architecture
Our architecture diagram clearly illustrates the well-known 3-tier architecture model (numbered in green in the diagrams). Sometimes you will have more, but rarely will you have less. Why is this? Because by following clean code and SOLID principles you will always separate the concerns of presentation (view models, API models, JSON structure, etc), persistence (databases, 3rd-parties, file systems) and your cross-cutting dependencies and domain models from each other.
Conclusion
We have seen in part 2 how we derived the solution architecture by following logical thought processes, and how it emerged that there are even more dependencies and how those dependencies should ideally be structured. We continued to follow SOLID by inverting dependencies and containing (or deferring) functionality to separate entities to put us in a better position to design in isolation.
Emergence
It is important to realize that we never know everything, and you’ll learn through experience that you cannot design for all possible futures, outcomes and exceptions. You can only design for what you know at this moment, and then you add some common sense to that. It is a continuously emergent process and this is why it is important that we can adjust our design quickly and without fear of breaking everything that has come before. This is where clean code and SOLID principles help us.